
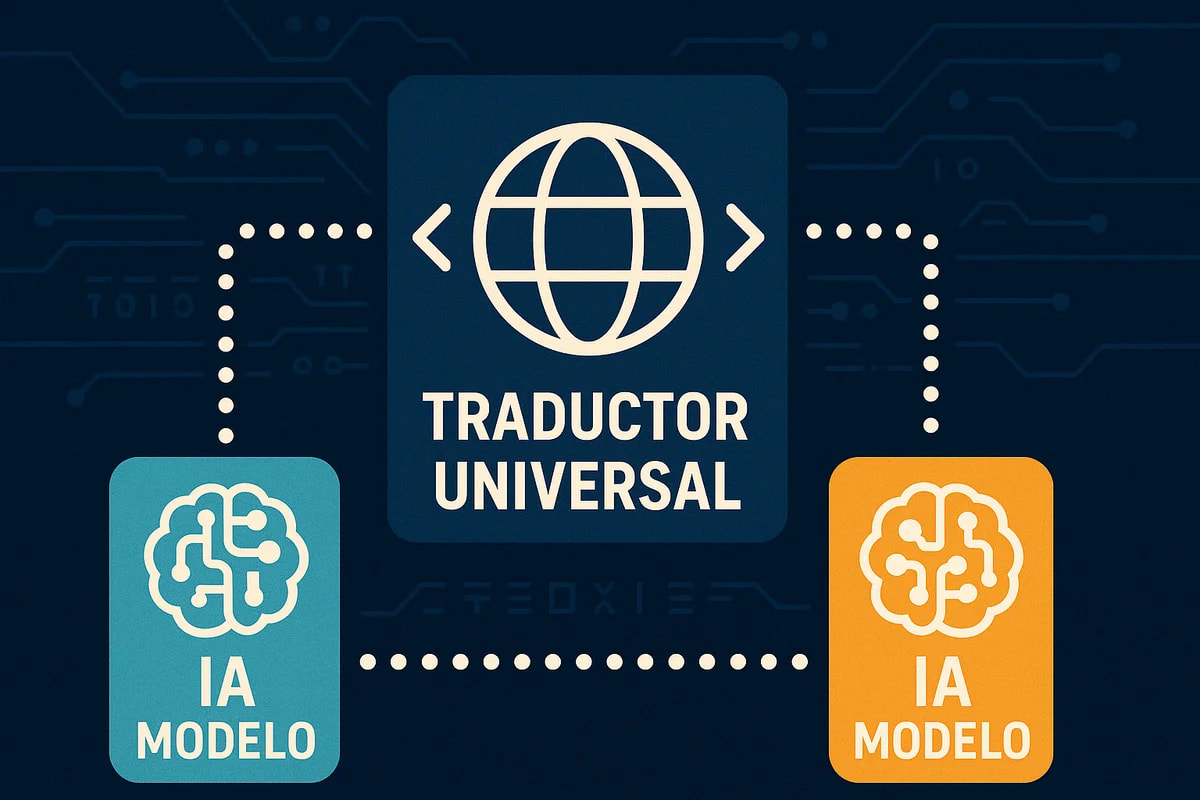
El problema de la incomunicación entre modelos de IA
Así como las personas de diferentes países hablan distintos idiomas, los modelos de IA también crean diversos "lenguajes" internos: un conjunto único de tokens que solo entiende cada modelo. Hasta ahora, los modelos desarrollados por diferentes empresas no podían comunicarse directamente, colaborar ni combinar sus fortalezas para mejorar su rendimiento.
Los modelos de aprendizaje profundo como ChatGPT y Gemini son herramientas potentes, pero presentan importantes inconvenientes: son lentos y consumen mucha potencia de procesamiento. En 2022, las principales empresas tecnológicas desarrollaron un método llamado decodificación especulativa, donde un modelo pequeño y rápido realiza una primera suposición al responder consultas, y un modelo más grande revisa y corrige la respuesta si es necesario.
Sin embargo, la decodificación especulativa tenía una gran limitación: ambos modelos debían "hablar" el mismo lenguaje digital, lo que significaba que los modelos desarrollados por diferentes empresas no podían combinarse. Solo los gigantes tecnológicos podían beneficiarse porque tenían acceso a modelos pequeños y grandes que compartían el mismo lenguaje interno.
"En cambio, una startup que buscaba beneficiarse de la decodificación especulativa tenía que entrenar su propio modelo pequeño que se ajustara al lenguaje del modelo grande, lo cual requiere una gran experiencia y costosos recursos computacionales", explica Nadav Timor, estudiante de doctorado que dirigió el desarrollo.
La solución: algoritmos de traducción universal
Para superar la barrera del idioma, los investigadores idearon dos soluciones innovadoras. Primero, diseñaron un algoritmo que permite a un modelo de IA traducir su salida desde su lenguaje de tokens interno a un formato compartido que todos los modelos pueden comprender.
En segundo lugar, crearon otro algoritmo que impulsa a dichos modelos a basarse principalmente en tokens que tienen el mismo significado en todos los modelos, de forma similar a palabras como "banana" o "internet", que son casi idénticas en todos los lenguajes humanos.
"Al principio, nos preocupaba que se perdiera demasiada información en la traducción y que los diferentes modelos no pudieran colaborar eficazmente", afirma Timor. "Pero nos equivocamos. Nuestros algoritmos aceleran el rendimiento de los LLM hasta 2,8 veces, lo que se traduce en un ahorro considerable en potencia de procesamiento".
Impacto y adopción mundial
La importancia de esta investigación ha sido reconocida por los organizadores de la Conferencia Internacional sobre Aprendizaje Automático (ICML), quienes seleccionaron el estudio para su presentación pública, una distinción otorgada solo a alrededor del 1% de las 15.000 propuestas recibidas este año.
En los últimos meses, el equipo publicó sus algoritmos en la plataforma de IA de código abierto Hugging Face Transformers, poniéndolos a disposición de desarrolladores de todo el mundo. Desde entonces, los algoritmos se han convertido en herramientas estándar para ejecutar procesos de IA eficientes.
Los nuevos algoritmos aceleran el rendimiento de los grandes modelos de lenguaje en 1,5 veces en promedio, permitiendo a los desarrolladores de IA combinar el poder de diferentes modelos que ahora pueden "pensar" como uno solo.
"Hemos solucionado una ineficiencia fundamental de la IA generativa", afirma Oren Pereg, investigador sénior de Intel Labs. "No se trata solo de una mejora teórica; se trata de herramientas prácticas que ya están ayudando a los desarrolladores a crear aplicaciones más rápidas e inteligentes".
Los gigantes tecnológicos que adoptaron la decodificación especulativa original se beneficiaron de un rendimiento más rápido y ahorraron miles de millones de dólares al año en costos de procesamiento, pero ahora esta tecnología está disponible para cualquier desarrollador.
Aplicaciones en dispositivos del futuro
Este desarrollo es especialmente importante para los dispositivos periféricos, desde teléfonos y drones hasta coches autónomos, que deben depender de una potencia de cálculo limitada cuando no están conectados a internet.
"Imagine, por ejemplo, un coche autónomo guiado por un modelo de IA. En este caso, un modelo más rápido puede marcar la diferencia entre una decisión segura y un error peligroso", añade Timor sobre las aplicaciones críticas de la tecnología.
Fuente: Instituto Weizmann de Ciencias





